
Time Series Prediction

time-series data preparation video tutorial part 1
code and results output, part 2
What’s Time Series
A time series is a series of data points indexed (or listed or graphed) in time order. Most commonly, a time series is a sequence taken at successive equally spaced points in time. Thus it is a sequence of discrete-time data. Examples of time series are heights of ocean tides, counts of sunspots, and the daily closing value of the Dow Jones Industrial Average and etc.
Time series algorithms divided into two major groups,
Classical method and Modern method which classical method mostly are based on classical statistic and basic mathematical operation whereas modern approaches are based on neural networks and Machin learning algorithms.
Classical Time Series Prediction Methods
Before exploring machine learning based methods for time series prediction, it is a good idea to know some about classical linear time series prediction methods. Classical time series prediction methods may be focused on linear relationships, nevertheless, they are sophisticated and perform well on a wide range of problems, assuming that your data is suitably prepared and the method is well configured.

In chart below you can find name of most important classical time series prediction method:
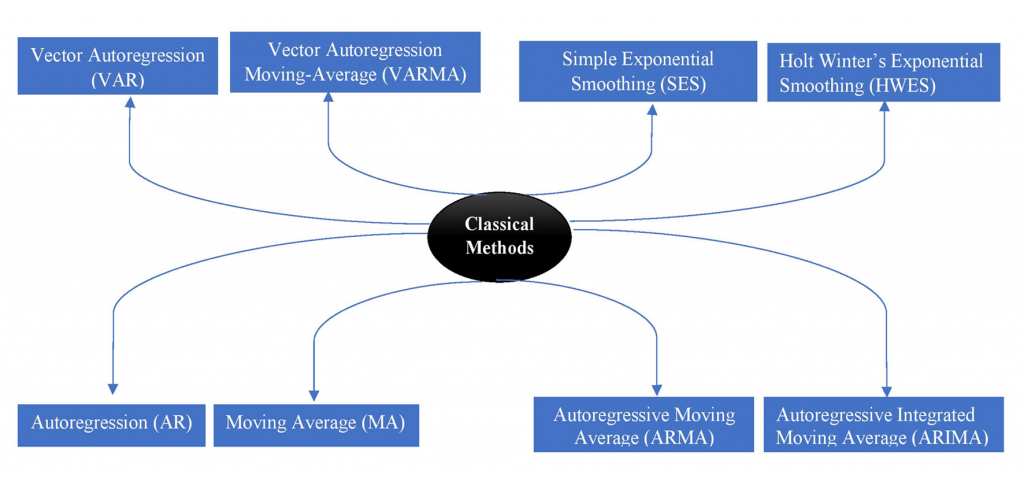
but there are many limitations come with these methods:
- Most of them require completedata, there are ways to deal with missing data but some missing values can really affect the models.
- They rely on linear In many traditional models, their assumptions are linearly based but not complex joint distribution based.
- They usually only deal with univariate In real world, we can see many dataset have multiple inputs. For instance, if we want to predict the air pressure in one area, it’s also helpful investigate the air pressures in other areas because they might have a potential effect on the given area
- They usually don’t work well in long term forecast. Probably only useful in one-step forecast.
Deeplearning Time Series Prediction Methods
Traditionally, time series forecasting has been dominated by linear methods because they are well understood and effective on many simpler forecasting problems. Deep learning neural networks are able to automatically learn arbitrary complex mappings from inputs to outputs and support multiple inputs and outputs.
In this article, we will look at different models of neural networks and their functionality to predict time series dataset.
Multilayer Perceptron MLP
Generally, neural networks like Multilayer Perceptron or MLPs provide capabilities that are offered by few algorithms, such as:
- Robust to Noise. Neural networks are robust to noise in input data and in the mapping function and can even support learning and prediction in the presence of missing values.
- Nonlinear. Neural networks do not make strong assumptions about the mapping function and readily learn linear and nonlinear relationships.
- Multivariate Inputs. An arbitrary number of input features can be specified, providing direct support for multivariate forecasting.
- Multi-step Forecasts. An arbitrary number of output values can be specified, providing
direct support for multi-step and even multivariate forecasting.
For these capabilities alone, feedforward neural networks may be useful for time series forecasting
Convolutional Neural Networks CNN
The focus on deep learning methods means that we don’t focus on many other important areas of time series forecasting, such as data visualization, how classical methods work, the development of machine learning solutions, or even depth and details on how the deep learning methods work.
Convolutional Neural Networks or CNNs are a type of neural network that was designed to efficiently handle image data.
The ability of CNNs to learn and automatically extract features from raw input data can be applied to time series forecasting problems. A sequence of observations can be treated like a one-dimensional image that a CNN model can read and distill into the most salient elements.
Automatic identification, extraction and distillation of salient features from raw input data that pertain directly to the prediction problem that is being modeled.
CNNs get the benefits of Multilayer perceptron for time series forecasting, namely support for multivariate input, multivariate output and learning arbitrary but complex functional relationships, but do not require that the model learn directly from lag observations. Instead, the model can learn a representation from a large input sequence that is most relevant for the prediction problem.
Long Short-Term Memory Networks (LSTMs)
Recurrent neural networks like the Long Short-Term Memory network or LSTM add the explicit handling of order between observations when learning a mapping function from inputs to outputs, not offered by MLPs or CNNs. They are a type of neural network that adds native support for input data comprised of sequences of observations.
- Native Support for Sequences. Recurrent neural networks directly add support for input sequence data.
This capability of LSTMs has been used to great effect in complex natural language processing problems such as neural machine translation where the model must learn the complex interrelationships between words both within a given language and across languages in translating form one language to another.
- Learned Temporal Dependence. The most relevant context of input observations to the expected output is learned and can change dynamically.
The model both learns a mapping from inputs to outputs and learns what context from the input sequence is useful for the mapping, and can dynamically change this context as needed.
Time Seris Data Prepration
Data Scaling
Time series data often requires some preparation prior to being modeled with machine learning algorithms.
For example, differencing operations can be used to remove trend and seasonal structure from the sequence in order to simplify the prediction problem. Some algorithms, such as neural networks, prefer data to be standardized and/or normalized prior to modeling.
Any transform operations applied to the series also require a similar inverse transform to be applied to the predictions. This is required so that the resulting calculated performance measures are on the same scale as the output variable and can be compared to classical forecasting methods.
lots of transformations exist, but in this article, I’ll talk about two popular of them:
- Standardization
- Normalization
Standardization
Standardization is a transform for data with a Gaussian distribution.
It subtracts the mean and divides the result by the standard deviation of the data sample. This has the effect of transforming the data to have mean of zero, or centered, with a standard deviation of 1. This resulting distribution is called a standard Gaussian distribution, or a standard normal, hence the name of the transform.
Normalization
Normalization is a rescaling of data from the original range to a new range between 0 and 1.

Normalize or Standardize?

Normalization vs. standardization is an eternal question among machine learning newcomers. Let me elaborate on the answer in this section.
- Normalization is good to use when you know that the distribution of your data does not follow a Gaussian distribution. This can be useful in algorithms that do not assume any distribution of the data like K-Nearest Neighbors and Neural Networks.
- Standardization, on the other hand, can be helpful in cases where the data follows a Gaussian distribution. However, this does not have to be necessarily true. Also, unlike normalization, standardization does not have a bounding range. So, even if you have outliers in your data, they will not be affected by standardization.
However, at the end of the day, the choice of using normalization or standardization will depend on your problem and the machine learning algorithm you are using. There is no hard and fast rule to tell you when to normalize or standardize your data. You can always start by fitting your model to raw, normalized and standardized data and compare the performance for best results.
Considerations for Model Evaluation
We have mentioned the importance of being able to invert a transform on the predictions of a model in order to calculate a model performance statistic that is directly comparable to other methods.
Additionally, another concern is the problem of data leakage.
these transforms estimate coefficients from a provided dataset that are then used to transform the data
- Standardization: mean and standard deviation statistics.
- Normalization: min and max values.
These coefficients must be estimated on the training dataset only.
Once estimated, the transform can be applied using the coefficients to the training and the test dataset before evaluating your model.
If the coefficients are estimated using the entire dataset prior to splitting into train and test sets, then there is a small leakage of information from the test set to the training dataset. This can result in estimates of model skill that are optimistically biased.
Indeed it depends on your dataset size and how it is rich if you have a big dataset you can suppose that test and train coefficients are almost equal. So for the big and rich dataset, you can gain the coefficient before dividing the dataset into test and train but for small size dataset with bad behavior in amplitude, variance, and trend you should estimate coefficient from the training dataset to understand the performance of the network on the test dataset
Time Series Data Reshaping
The question is how to transform a time series into a form suitable for supervised learning?
Deep learning methods are trained using supervised learning and expect data in the form of samples with inputs and outputs. So we should reshape our Time Series Sequence to Input/output Format.
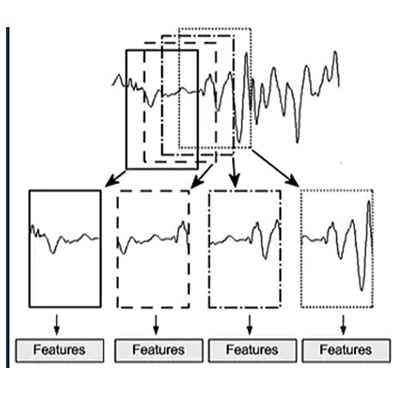
Given a sequence of numbers for a time series dataset, we can restructure the data to look like a supervised learning problem. We can do this by using previous time steps as input variables and use the next time step as the output variable.
Lag(s) or delay(s) features are the classical way that time series forecasting problems are transformed into supervised learning problems. The simplest approach is to predict the value at the next time (t+1) given the value at the current time (t). The supervised learning problem with shifted values looks as follows:
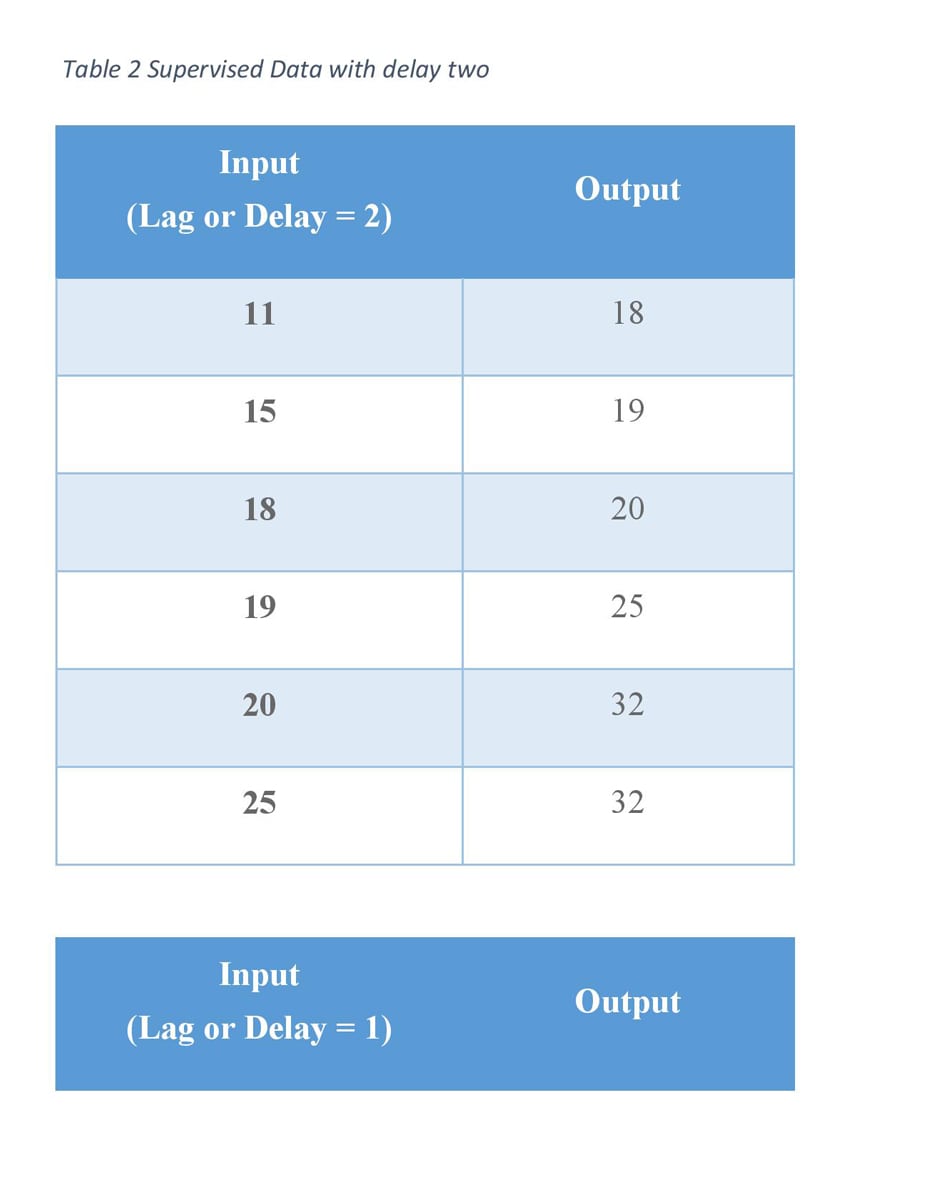
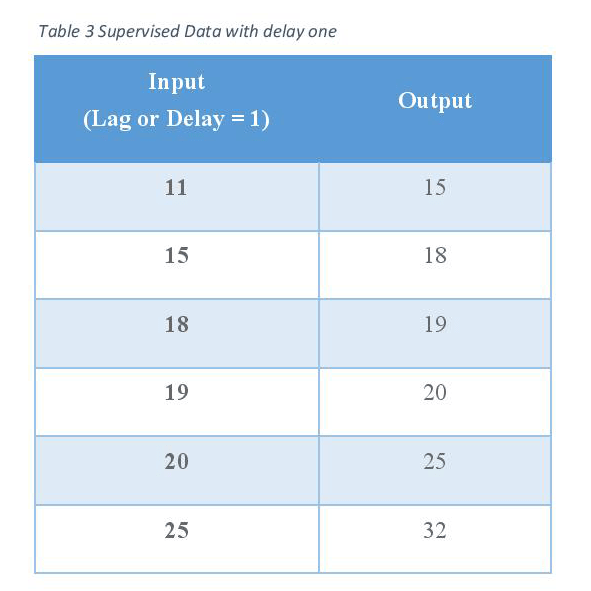
And also we can use a set of lags in our work in which the smallest lags (Minimum lags value) show our prediction horizon and the biggest lags (maximum lags value) shows how we should cut from our beginning of dataset.
so if we want to predict one step ahead data of Traffic of New York and we know for this prediction, value of one, two and seven days before of now day is important we should set our delays like below:
Delays = [1, 2, 7]
and for instance, if we want to predict three steps ahead by one prediction, we should use delays in this format:
Delays = [3, 4 ,5, 6,…]
Prediction
There are some solution when you need to predict multiple time steps ahead in future.
Predicting multiple time steps into the future is called multi-step time series forecasting. There are three main strategies that you can use for multi-step forecasting.
First one, Strait Multi-step Prediction:
Generally, time series forecasting describes predicting the observation at the next time step.
This is called a one-step forecast, as only one time step is to be predicted.
There are some time series problems where multiple time steps must be predicted. Contrasted to the one-step forecast, these are called multiple-step or multi-step time series forecasting problems.
Recursive Multi-step Prediction
The recursive strategy involves using a one-step model multiple times where the prediction for the prior time step is used as an input for making a prediction on the following time step.
Evaluation
It is important to evaluate prediction accuracy using genuine forecasts. Consequently, the size of the residuals is not a reliable indication of how large true forecast errors are likely to be. The accuracy of prediction can only be determined by considering how well a model performs on new data that were not used when fitting the model.
it is common practice to separate the available data into two portions, training and test data, where the training data is used to estimate any

parameters of a forecasting method and the test data is used to evaluate its accuracy.
license agreement
Copyright (c) 2020, Abolfazl Nejatian All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution
* Neither the name of nor the names of its
contributors may be used to endorse or promote products derived from this
software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS”
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
it’s so nice
good
very productive code
thank you very much for your useful comment
good for you